计划写一系列关于 Vue 原理的文章,学习理解后分享印象更深!
众所周知 ,Vue 文件中写的 <template></template> 标签都会被 vue-loader 转化成 AST 语法树,而后再根据 AST 语法树生成 render 渲染函数,最后渲染并挂载在页面上。
本文简单实现下 Vue 模板编译原理的第一步: AST 语法树的生成过程!
首先定义我们的原始代码:
<template>
<div id="app" style="color:red;">
hello
<span>{{name}}</span>
</div>
</template>
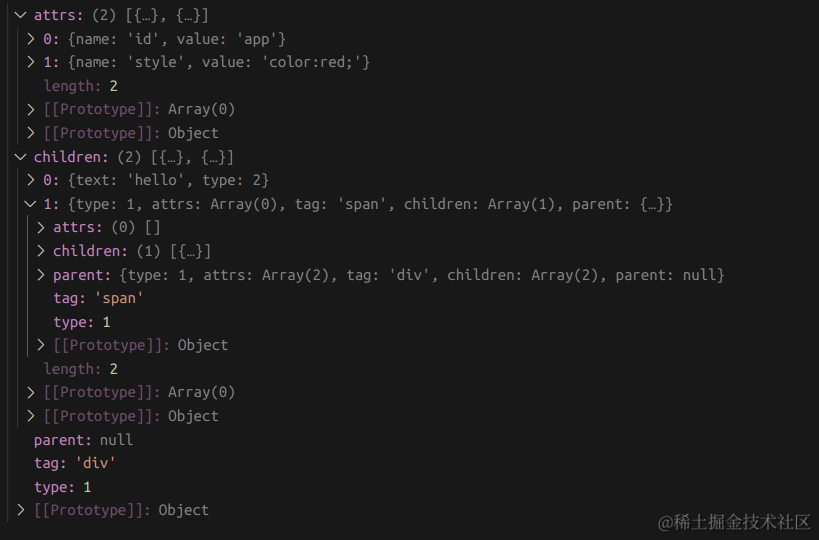
目标 AST 结构:
{
type: 1,
attrs: [
{name: 'id',value: 'app'},
{name: 'style',value: 'color:red;'}
],
tag: 'div',
children: [
{text: 'hello',type: 2},
{
type: 1,
attrs: [],
tag: 'span',
children: [
{text: '{{name}}',type: 2},
],
parent: parent // 指向父元素
}
],
parent: null
}
- 获取模板内容
通过正则匹配出 template 的 innerHTML
const content = template.match(/<template[^>]*>((?:.|\n|\r)*)<\/template>/)
// content[1] 为目标结果:
// <div id="app" style="color:red;">
// hello
// <span>{{name}}</span>
// </div>
- 匹配标签
先看几个匹配标签正则:
var attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/ // 匹配属性
var ncname = "[a-zA-Z_][\\-\\.0-9_a-zA-Z]*"; // 匹配 div or div-test
var qnameCapture = "((?:" + ncname + "\\:)?" + ncname + ")"; // 匹配 div:name
var startTagOpen = new RegExp(("^<" + qnameCapture)); // 匹配开始标签 <div:name
var startTagClose = /^\s*(\/?)>/; // 匹配开始标签结束 /> or >
var endTag = new RegExp(("^<\\/" + qnameCapture + "[^>]*>")); // 匹配结束标签 </div>
你会发现标签匹配都有个起始符^,这是因为 vue 模板正则匹配过程是匹配操作一个删一个,如:
<div>name</div> 匹配到开始标签 <div 之后,便会删除该内容,剩下 >name</div>,接着匹配到开始标签结束 >, 便剩下 name</div>,以此类推到最后一个标签符。
另外上述标签正则有个共性是,匹配结果第二个元素都为标签名,如 const match = '<div>'.match(startTagOpen), match 的第一个元素match[0]为 <div,第二个元素 match[1] 为 div
- 定义 parseHTML 方法
因为是不断匹配不断操作,因此采用 while 循环, 代码有点长,耐心看完
let root = null
function parseHTML(html) {
while(html) {
// 找出第一个 "<" 的字符索引
const charIndex = html.indexOf('<')
// 如果刚好是第一个字符,有可能是开始标签,也有可能是结束标签
if (charIndex === 0) {
const startTagMatch = html.match(startTagOpen)
let endTagMatch
if (startTagMatch) {
// 如果是开始标签,则获取标签名和属性
const tagName = startTagMatch[1]
const attrs = []
// 匹配结束了就删除
html = html.substring(startTagMatch[0].length)
// 开始匹配属性
let startTagEndMatch, attrMatch
while(!(startTagEndMatch = html.match(startTagClose))
&& (attrMatch = html.match(attribute))) {
attrs.push({
name: attrMatch[1],
value: attrMatch[3] || attrMatch[4] || attrMatch[5]
})
// 匹配结束了就删除
html = html.substring(attrMatch[0].length)
}
if (startTagEndMatch) {
// 匹配结束了就删除
html = html.substring(startTagEndMatch[0].length)
}
// 处理内容,生成 ast 树
handleTagStart(tagName, attrs)
} else if (endTagMatch = html.match(endTag)) {
// 如果是结束标签
const tagName = endTagMatch[1]
handleTagEnd(tagName)
// 匹配结束了就删除
html = html.substring(endTagMatch[0].length)
}
} else if (charIndex > 0) {
// charIndex 大于0, 说明 “<” 前面还有字符,处理下字符
const chars = html.substring(0, charIndex)
handleChars(chars)
// 匹配结束了就删除
html = html.substring(chars.length)
}
}
return root
}
- 生成 AST 语法树
在匹配标签过程中我们执行了三个方法 handleTagStart() handleTagEnd() handleChars(), 我们利用这三个方法生成 AST 语法树,在实现函数之前定义两个变量: currentParent 和 tagStack
- currentParent 用于标签开始时临时保存当前元素,供其子元素保存使用
- tagStack 标签元素栈, 如
[divElement],div 有个子标签 p, 则往栈中增加 p 标签元素,[divElement, pElement], 当 p 标签匹配结束后删除最后一个标签元素,剩下[divElement], 根据此标签元素栈也可以明确元素之间的父子关系
实现 handleTagStart 方法
function handleTagStart(tagName, attrs) {
const element = {
type: 1,
attrs,
tag: tagName,
children: [],
parent: null // 父节点对象
}
// 在 parseHTML 的时候我们定义了根节点对象 root
if (root === null) {
// 当 root 为 null 时,说明此时节点为根节点
root = element
}
currentParent = element // 保存给后面匹配到的子节点元素使用
tagStack.push(element)
}
实现 handleTagEnd 方法
function handleTagEnd(tagName) {
// 匹配到结束标签,此时取出栈中最后一个元素
const element = tagStack.pop()
if (element && tagName === element.tag) {
// 如果标签名一样,说明结构正常
// 此时应修改 currentParent 的指向, 指向栈中最后一个元素
currentParent = tagStack[tagStack.length - 1]
// 匹配结束标签时才确定父子关系
if(currentParent){
element.parent = currentParent
currentParent.children.push(element)
}
}
}
实现 handleChars 方法
字符对象比较简单,没有子元素,也不需要指向父元素
function handleChars(text) {
// 去除多余空白符
text = text.replace(/\s+/g, '')
if (text){
currentParent.children.push({
text,
type: 2
})
}
}
最后执行 parseHTML, parseHTML(content[1])并打印结果,符合预期!